【入門】ApacheSpark/Sparkシェルで分散処理する方法!
Apache Sparkを分散処理する方法を知っていますか。本記事では、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関して紹介していきます。

目次
- 1Apache Spark 分散処理とは
- ・Sparkの得意/不得意
- ・Apache Sparkの構成
- 2Apache Sparkの環境構築
- ・インストール
- 3Apache Spark 分散処理の流れ
- ・系譜ステージへの分割
- ・ステージの実行要否を判定する
- ・タスクを生成する
- ・タスクを実行する場所を決める
- ・タスクの実行順序をスケジューリングする
- ・キーワード
- 4Apache Spark 分散処理を手軽に行う方法
- ・メモリ処理による高速化
- ・データのinput/output形式がいろいろと選択できる
- ・プログラミング形式
- ・Apache Sparkのインストール
- 5Apache Spark 分散処理とHadoop 分散処理との違い
- ・Hadoop の場合
- ・Sparkでは
- 6Apache Spark 分散処理のデータのI/O
- ・ファイルのロードとセーブ
- ・Scala/Java/R/Pythonなどに対応(APIが用意されてる)
- ・多彩なライブラリ
- ・複数の導入シナリオ(スタンドアロン/YARN/Mesos/組み込み/クラウド)
- ・幅広い処理モデル(バッチ/インタラクティブ/ストリーミング)
- 7Apache Spark 分散処理の導入にメリットのあるケース
- ・プロジェクトで扱うデータが大量である場合
- ・データの高速処理(リアルタイム性)を求められている場合
- ・Hadoopを既に使っている場合
- ・大規模データを扱う機械学習を行う場合
- ・まとめ
- ・合わせて読みたい!方法に関する記事一覧
Apache Spark 分散処理とは

Apache Spark 分散処理とは何か知っていますか。Apache Sparkとは、オープンソースの分散処理フレームワークのことです。
分散処理でよく知られているのはhadoopですが、hadoopがhdfsと呼ばれる独自のファイルシステムを通し、処理を実行していきます。
Apache Sparkとは「RDD(Resilient Distributed Dataset)」と呼ばれる耐障害耐性分散可能なデータもしくはセットをオンメモリで実行できるために、 高速な分散処理が実現できるのです。
Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関して紹介していきます。
Sparkの得意/不得意

以下ではSparkの得意もしくは不得意なことを紹介していきます。
得意
Apache Sparkの得意なことは以下の4つです。
- Hadoopで加工したのちのドリルダウン分析
- TB級までのデータを扱うシステム
- サンプリングが有効でないロングテールのデータ分析
- 数秒~数分程度のHadoopよりも短いレスポンスが必要な処理
不得意
Apache Sparkの不得意なことは以下の3つです。
- クラスタ全体のメモリに乗りきらない巨大なデータ処理(TB以上)
- 大きなデータセットを少しずつ更新する処理
- 秒以下の時に短いレスポンスが必要な処理
Apache Sparkの構成

Apache Sparkの構成は以下のとおりです。またApache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示を紹介します。
- Spark Core Sparkの基本機能を提供して、RDDと呼ばれている耐障害耐性分散可能なデータもしくはセットを提供する
- Spark Streaming データストリームの処理を提供して、ツイッターからリアルタイムデータの取得などに使用できる。
- Spark SQL 構造化データに対するアクセス機能を提供して、hiveSQLやクエリを使ってJSONなども扱える。
- Mlib 汎用的な機械学習ライブラリを取得し、word2vecを使った類似後分類などができる
- Graph X グラフ理論に基づく計算を提供して、ソーシャルグラフを扱う場合に役立つ
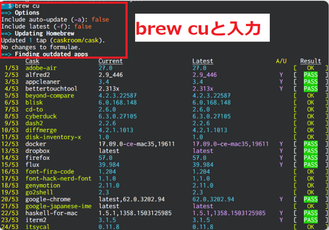 「brew Cask」でMacにアプリをインストールする方法!
「brew Cask」でMacにアプリをインストールする方法!Apache Sparkの環境構築

続いてApache Sparkの環境構築について紹介していきます。インストールに関して解説します。そしてApache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても紹介します。
インストール

上の画像のインストールにより以下の3種類の対話型実行環境も同時にインストールされるため、デバックの際は非常に良心的ですね。
- spark-shell (Scala)
- pyspark (python)
- sparkR (R言語)
Macでのインストール

Apache Sparkの環境構築では、Macでのインストールする必要があります。
Windowsでのインストール

Macでのインストール以外にも、WindowsでインストールしてもApache Sparkの環境構築をできます。
また、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示についてもみていきましょう。
 チャットゲームアプリ無料おすすめを紹介!【スマホ】
チャットゲームアプリ無料おすすめを紹介!【スマホ】Apache Spark 分散処理の流れ

Apache Spark 分散処理の流れでは、以下の6つに着目していきましょう。そしてApache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても紹介します。
- 系譜ステージへの分割
- ステージの実行要否を判定する
- タスクを生成する
- タスクを実行する場所を決める
- タスクの実行順序をスケジューリングする
- キーワード
系譜ステージへの分割

Apache Spark 分散処理では、まず系譜ステージへの分割をしてください。
データのパーティショニングについて
Apache Sparkのパーティショニングとは、データを複数に分割して格納することを指します。データを分割することにより、性能や運用性が向上して、故障の影響を局所化することが可能です。
ステージの実行要否を判定する

Apache Sparkの系譜ステージへの分割をした次には、ステージの実行要否を判定していきましょう。
また、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても解説します。
タスクを生成する

ステージの実行要否を判定したら、タスクを生成していきます。
タスクを実行する場所を決める

続いてタスクを生成したら、タスクを実行する場所を決めてください。
タスクの実行順序をスケジューリングする

タスクを実行する場所を決めたら、タスクの実行順序をスケジューリングしていきましょう。
キーワード

タスクの実行順序をスケジューリングした後に、キーワードを決めて完了です。
 【合成加工アプリ】「合成スタジオ」の使い方をくわしく解説!
【合成加工アプリ】「合成スタジオ」の使い方をくわしく解説!Apache Spark 分散処理を手軽に行う方法

ここでは、Apache Spark 分散処理を手軽に行う方法を紹介していきます。Lightbend社のリアクティブ開発プラットフォームである「Lightbend Reactive Platform」を使用し、実際にリアクティブなアプリケーションを開発しました。
Lightbend Reactive Platformを構成するプロダクトの一つである「Apache Spark」は分散処理フレームワークのことです。
分散処理フレームワークとは、大量のデータを複数コンピュータによって並列処理させて、処理を短時間で実行させるための仕組みを持ったフレームワークのことを指します。
また、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても注目していきましょう。

代表的な分散処理フレームワークは、Apache Hadoopです。Hadoopは、テキストデータやアクセスログといった大量のデータの蓄積あるいは分析を分散処理技術によって実現するのです。
「大量のデータ」を「分散処理(複数の環境で並列に実行できる)」で効率良く処理できる点がポイントになります。
Hadoopは「HDFS」と呼ばれる分散ファイルシステムと「MapReduce」という分散処理を行うための方法から構成されているのです。分散処理フレームワークを使ったデータ分析とその利用は、近年では一般的になっています。

様々な業種で分散処理フレームワークにより分析されたデータが活用されています。しかし、課題もあるのです。Hadoopの場合に、ディスクベースのアーキテクチャで大量のデータを効率良く処理するための設計となります。
したがって、処理のレイテンシも決して小さくなく、用途によっては非常に長く時間がかかります。このような問題によって、もっと手軽に短時間で処理を行いたいという要件が出てきているのです。
そこで活躍するものがApache Sparkです。Apache Sparkはメモリ上でデータの処理をすることによって高速化を実現しています。ディスクアクセスを多用するHadoopとは違い、機械学習などの用途に向いているのです。
メモリ処理による高速化

HadoopのMapReduceはI/O処理時にディスクへのアクセスをしていきます。それと比較してみると、Apache Sparkの場合には処理データをメモリ上で展開することによりI/O処理の高速化を実現しているのです。
なお、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関してもみていきます。
データのinput/output形式がいろいろと選択できる

Apache Sparkの場合には、HDFSの使用が絶対に必要ではありません。HDFS以外にOpenStack SwiftやAmazon S3を利用できます。
プログラミング形式

Apache Sparkを制御するために、Scala・Java・PythonなどのAPIが提供されているのを知っていますか。また、Datasetへのアクセス方法としてSpark SQLと呼ばれる言語を使用したり、もしくはRDBからデータを取得したりできます。
Apache Sparkのインストール

Apache Sparkの動作を試してみるには、Homebrewをインストールする方法もおすすめです。
また、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても注意してください。
Sparkシェルとは
Sparkシェルとは、Sparkのコマンドをコマンドラインから入力し、対話的に実行内容を確認できるモードのことです。
Sparkシェルの起動
まずはSparkシェルを起動してから、spark-shellコマンドを実行することによってScalaのSparkシェル用REPLが起動してください。
Sparkシェルでログファイルにアクセス
Sparkシェルでログファイルにアクセスしていきます。まずは「log.csv」という名前で以下のようなファイルを準備してください。
- 100,taro,30,2018-03-20 10:41:20 101,hanako,20,2018-03-03 11:32:34 102,Mike,35,2018-01-28 20:20:11
scという変数名によってSparkContextのインスタンスが使用できるため、textFike関数を使用してログファイルを読み込みます。
- scala> val file = sc.textFile("./log.csv") file: org.apache.spark.rdd.RDD[String] = ./log.csv MapPartitionsRDD[1] at textFile at <console>:24(読み込んだファイルの行数を数えることができる)
- scala> file.count() res0: Long = 3(先頭行はfirst関数で取得できる)
- scala> file.first() res1: String = 100,taro,30,2018-03-20 10:41:20(filterを使って任意の条件にマッチした行を取得することも可能)
- scala> file.filter(row => row.contains("hanako")).count res4: Long = 1
Webインタフェース「Spark shell application UI」で確認

Webインタフェース「Spark shell application UI」で確認しましょう。ここまではコンソールだけで進めてきました。しかし、Sparkシェルを起動することfr「Spark shell application UI」というWebインタフェースのサービスも起動されます。
つまり、ブラウザでSparkシェルのジョブステータスや設定情報を確認できるということです。。Sparkシェルを起動すると、起動時に下記のようなログメッセージが表示されるため、ブラウザでアクセスしていきましょう。
「Spark context Web UI available at http://{your local ip}:4040」というように実行したコマンドのステータスや実行時間などが表示されています。
 音程の練習に便利な無料おすすめアプリを紹介!
音程の練習に便利な無料おすすめアプリを紹介!Apache Spark 分散処理とHadoop 分散処理との違い

続いて、Apache Spark 分散処理とHadoop 分散処理との違いを紹介していきましょう。またApache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関してもみていきます。
Hadoop の場合

Hadoopは需要のあるツールでどんどん活用の場が増えてきました。しかしながら、そのようなHadoopにも欠点があります。その欠点を補う形で登場したのがSparkになります。Hadoopの並列処理には下記のような欠点がああるのです。
- 個々のコンピュータのメモリをうまく活用する設計ではない
- 同じ処理を複数行う場合に、都度ストレージのアクセスが発生する
- 同じデータを何回も扱う場合にストレージのアクセスが発生する
Sparkでは

一方でSparkは上記のような課題を解決するために誕生したものです。「Resilient Distributed Datasets」という分散共有メモリの仕組みがあります。そして、データはパーティション化され、複数マシンのメモリで管理されるのです。
つまり今までその都度ストレージにアクセスしていたものが、インメモリで実行できるようになったということです。
 【Android】「スリープタイマー」アプリで寝落ち防止する方法!
【Android】「スリープタイマー」アプリで寝落ち防止する方法!Apache Spark 分散処理のデータのI/O

ここではApache Spark 分散処理のデータのI/Oに関する内容です。以下の5つについて深掘りします。なお、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関してもみていきます。
- ファイルのロードとセーブ
- Scala/Java/R/Pythonなどに対応(APIが用意されてる)
- 多彩なライブラリ
- 複数の導入シナリオ(スタンドアロン/YARN/Mesos/組み込み/クラウド)
- 幅広い処理モデル(バッチ/インタラクティブ/ストリーミング)
ファイルのロードとセーブ

例えば、bin/data内のJSONファイルをまとめ、一つのRDDとして読み込めます。ここではJSONの扱いは触れません。ただjavaのJSONライブラリにはhttps://github.com/FasterXML/jackson などがあります。
しかしながら、その場合も一度テキストとして読み込んでから処理することが必須条件です。
ファイルの圧縮

Sparkではストレージの容量節約、もしくは通信コストを下げるために、textFile()などの入力フォーマット群で幾つかの種類の圧縮を自動的に処理してくれるのです。
しかしながらこれらの圧縮は、ファイルシステムへ書き出される場合のみ利用可能でデータベースなどにはSpark側からはできません。
そして、圧縮のフォーマットにより、分散させていろんなワーカーから読めないものがあり、ボトルネックとなります。複数のワーカーから読み出し可能なフォーマットを「スプリット可能」と言うことを覚えておきましょう。
Scala/Java/R/Pythonなどに対応(APIが用意されてる)

Scala/Java/R/Pythonなどに対応していて、様々な言語をサポートし、サードパーティー製のライブラリも組み込みやすくなっています。
多彩なライブラリ

下記のような多彩なライブラリがあるので確認しておきましょう。
- Spark SQL: 構造化データや表形式データを扱うSpark Streaming: ほぼリアルタイムでストリーム・データを処理する
- MLlib: 機械学習を行う(コンポーネントとしてspark.mllibとspark.mlがあるが前者が非推奨になった模様)
- GraphX: グラフ処理を行う
複数の導入シナリオ(スタンドアロン/YARN/Mesos/組み込み/クラウド)

Apache Mesosもサポートしているのを知っていますか。企業向けで最もメジャーなのはHadoop YARN(Hadoopコアの一部)でも、もちろんサポートしています。
そして、Spark Standaloneと呼ばれる小規模ビルトイン・クラスタ・システムも含まれていて、小規模クラスタ・テストなどの用途でのデプロイに適しているのです。
一方分散モードでは、Sparkは一つのセントラルコーディネータ(ドライバ)と、多くの分散ワーカー(エグゼキュータ)を持つマスター/スレーブアーキテクチャを利用していきましょう。
そのドライバ単体でjavaのプロセスとして動作し手から、各エグゼキュータも個別のjavaプロセスとして動作してください。
Sparkのアプリケーション

上記の画像のように、Sparkのアプリケーションはクラスタマネージャーと呼ばれる外部サービスを使用して、複数のマシン上で起動されています。その場合には、spark-submitコマンドにてアプリケーションが投入されるのです。
このコマンドは、ドライバプログラムを起動し手からユーザが指定したmain()メソッドを呼び出すという仕組みです。その後に、ドライバプログラムはクラスタマネージャに接続して、エグゼキューターを起動するためのリソースを要求します。
続いて、クラスタマネージャがドライバプログラムの代理としてエグゼキュータを起動していきましょう。ドライバプログラムは、ユーザアプリケーションを実行してから、プログラム中のRDDの変換やアクションに基づきます。

それから、タスクという形で処理をエグゼキュータに送りつけましょう。エグゼキュータのプロセスでタスクが実行されてから計算結果が保存されます。
そして、ドライバのmain()メソッドが終了する、もしくは main()メソッドからSparkContext.stop()が呼ばれることによって、ドライバはエグゼキュータを終了させます。
次に、クラスタマネージャから取得したリソースを開放して完了です。これが一連のSparkアプリケーションの流れです。
ドライバ
ドライバとは、作成するプログラムのmain()関数を実行するプロセスのことです。SparkContextの生成やRDDの生成を行って、変換やアクションを実行します。
そして、ユーザプログラムのタスクの変換と、エグゼキュータ上のタスクのスケジューリングの処理を実行に際して責任を負うことがあります。
なお、前者に関してはSpark処理の流れや系譜のステージへの分割で説明したとおり、ユーザのプログラムをタスクという実行単位に変換することです。

SparkのプログラムはRDDを生成してから変換し、アクションを行うという構造を取っています。次に、その操作で構築される有向循環グラフを生成するのです。ステージ群にはタスクが複数含まれています。
また、後者に関してもSpark処理の流れ[補足] / Ⅴ. タスクの実行順序をスケジューリングするで記述したとおり、Sparkのドライバはエグゼキュータ群の個々のタスクのスケジュールを調整するのです。
エグゼキュータ群は起動時に自分自身をドライバに対して登録するので、ドライバは自分のアプリケーションのエグゼキュータの様子を常時に把握できます。
エクゼキュータ
Sparkのエグゼキュータとは、Sparkのジョブの個々のタスクの実行を受け持つワーカープロセスのことです。エグゼキュータはSparkのアプリケーション起動時に一度起動されてから、そのアプリケーションが起動している間は動作し続けます。
なお、Sparkのアプリケーションはエグゼキュータ群に障害がある場合でも処理を継続できます。主なエグゼキュータの役割としては、アプリケーションを構築するタスク群を実行し結果をドライバに返すことでしょう。
それから、ユーザプログラムによってキャッシュされるRDDのインメモリストレージを各エグゼキュータ内で動作するブロックマネージャと呼ばれるサービスを通して提供することもあげられます。
幅広い処理モデル(バッチ/インタラクティブ/ストリーミング)

幅広い処理モデル(バッチ/インタラクティブ/ストリーミング)では、特にインタラクティブシェルがとても便利になっています。
また、その都度ビルドする必要がないためロジックの試作など効果の確認サイクルを早く回せるのです。見た目も使い方もRubyでのirbのようなものです。
 【写真共有アプリ】「EyeEm」の使い方をくわしく解説!
【写真共有アプリ】「EyeEm」の使い方をくわしく解説!Apache Spark 分散処理の導入にメリットのあるケース

最後にApache Spark 分散処理の導入にメリットのあるケースを以下の4つ紹介します。
- プロジェクトで扱うデータが大量である場合
- データの高速処理(リアルタイム性)を求められている場合
- Hadoopを既に使っている場合
- 大規模データを扱う機械学習を行う場合
プロジェクトで扱うデータが大量である場合

Sparkはテラバイトは当然のことながら、ペタバイト級のデータ量も扱うこともできます。1台のコンピュータで処理できないデータがある場合はSparkがおすすめします。
データの高速処理(リアルタイム性)を求められている場合

計算処理が1週間ほどかかる場合でも、Sparkを活用することによって1時間で終わらせれます。このような高速化によりビジネス上のメリットがあるのです。
Hadoopを既に使っている場合

Sparkのアプリケーションは、HadoopのYARN(Yet Another Resource Negotiator)クラスタ上でも実行可能です。
今後はJavaでMapReduce処理を書くのではなく、Sparkで書く場合の方が簡潔かつ質の高い並列処理プログラムが作成できるでしょう。
なお、HDFSのデータを分析することもできます。「Hadoopから移行」ではなく「Hadoopと共存」という形で導入できるのがSparkの魅力です。
大規模データを扱う機械学習を行う場合

小規模なデータの場合には、Sparkを使わずに機械学習モデルを作っても十分です。しかしながら、分析対象が大規模の場合にはSparkはおすすめです。
線形回帰・ロジスティック回帰・クラスタリングなど、一般的な機械学習のアルゴリズムも備えているのでぜひ試してみてください。大規模データの分析にSparkを応用しましょう。
まとめ

今回の記事では【入門】ApacheSpark/Sparkシェルで分散処理する方法!というテーマで執筆しました。ApacheSpark/Sparkシェルで分散処理する際はぜひ参考にしてみてください。
また、Apache Sparkの分散処理する方法・入門方法・特徴・インストール・ログファイル・Webインタフェース・バージョン表示に関しても参考にしてみましょう。
合わせて読みたい!方法に関する記事一覧
 【iSyncr】AndroidスマホとiTunesを連携させる方法を紹介!
【iSyncr】AndroidスマホとiTunesを連携させる方法を紹介! 【個人間送金アプリ】チャージ方法/手数料などサービスを比較!
【個人間送金アプリ】チャージ方法/手数料などサービスを比較! 【Windows10】「Windows Defender」でフルスキャンする方法!
【Windows10】「Windows Defender」でフルスキャンする方法! 写真整理アプリ「Scene」でフォトブック作成する方法を紹介!
写真整理アプリ「Scene」でフォトブック作成する方法を紹介!